Представленный проект был создан в рамках хакатона генеративнымх медиа
ScienceMedia AI 2024. Данные, выводы и их визуализация нуждаются в доработке.
ScienceMedia AI 2024. Данные, выводы и их визуализация нуждаются в доработке.
Представленный проект был создан в рамках хакатона генеративнымх медиа
ScienceMedia AI 2024. Данные, выводы и их визуализация нуждаются в доработке.
ScienceMedia AI 2024. Данные, выводы и их визуализация нуждаются в доработке.






Кто ловил эти звуки неверного ритма,
Эти линии непараллельных сторон,
Кто твердил о величии Третьего Рима,
Тот не ведал – не Рим перед ним, Вавилон.
Эти линии непараллельных сторон,
Кто твердил о величии Третьего Рима,
Тот не ведал – не Рим перед ним, Вавилон.

Алла Арцис
Величественные храмы, дворцы и высокие зиккураты. Улицы, выложенные кирпичом, мозаика и лепнина
с изображениями божеств и царей на стенах зданий. Да, Вавилон когда-то был самым ярким и продвинутым городом Месопотамии. И жители его говорили на шумерском.
с изображениями божеств и царей на стенах зданий. Да, Вавилон когда-то был самым ярким и продвинутым городом Месопотамии. И жители его говорили на шумерском.
На этом языке появилось самое первое литературное произведение – «Эпос о Гильгамеше». 12 табличек
с угловатыми клиновидными штрихами – клинописью – дошли до наших дней среди полумиллиона других. Месопотамия оставила нам больше письменных источников, чем Древняя Греция, Египет и Рим вместе взятые. И сегодня ученые из Университета Торонто работают над проектом, который позволит автоматизировать расшифровку этих текстов с помощью искусственного интеллекта.
с угловатыми клиновидными штрихами – клинописью – дошли до наших дней среди полумиллиона других. Месопотамия оставила нам больше письменных источников, чем Древняя Греция, Египет и Рим вместе взятые. И сегодня ученые из Университета Торонто работают над проектом, который позволит автоматизировать расшифровку этих текстов с помощью искусственного интеллекта.

Как это работает? Ученые обучают нейросети
на примерах древних текстов, чтобы создать алгоритмы
для автоматического анализа и перевода клинописи. Это экономические и административные записи, такие как списки товаров и сделок. В них нет метафор, но тем они
и ценны для автоматической обработки.
на примерах древних текстов, чтобы создать алгоритмы
для автоматического анализа и перевода клинописи. Это экономические и административные записи, такие как списки товаров и сделок. В них нет метафор, но тем они
и ценны для автоматической обработки.
Современные технологии ускоряют процесс, который раньше занимал бы десятилетия. Это уникальная возможность сделать еще один шаг в естественной обработке древних языков и открыть миру наследие цивилизаций прошлого.
Пифагорейские тройки, библиотека редких книг и рукописей
Колумбийского университета, Нью-Йорк, США
Колумбийского университета, Нью-Йорк, США
The Epic of Gilgamesh, read by Karl Hecker



Представьте себе мир, где каждый звук, каждое слово несет в себе тайну тысячелетий. Люди общались на языках, которые после себя даже не оставили следов. Как узнать, что они говорили? Как понять, какие слова использовали наши далекие предки, если не осталось ни одной записи?
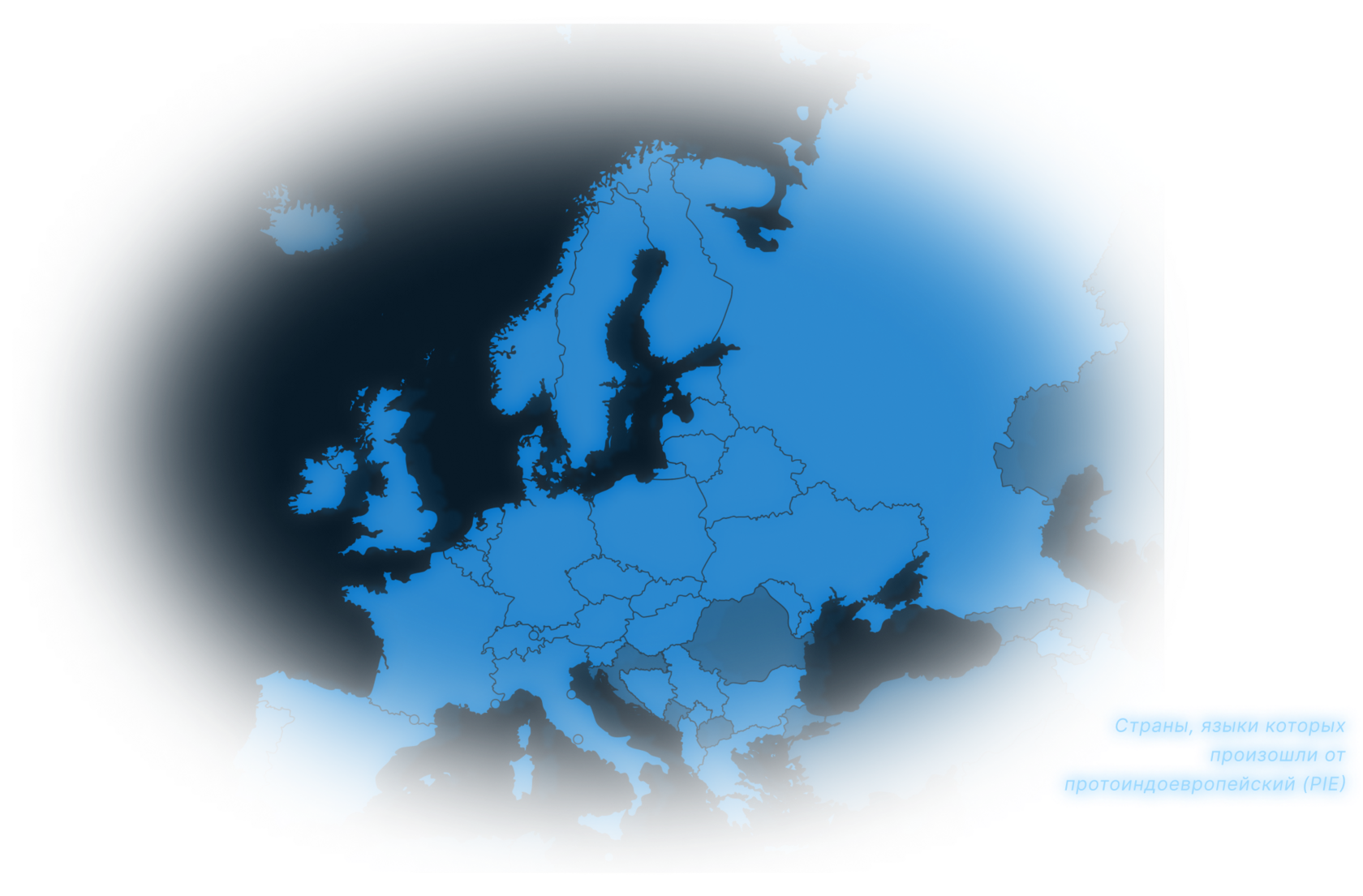
Протоязыки — это попытка восстановить тот самый первозданный звук, который когда-то связывал разные народы. Как, например, прото-германский язык, предшественник всех германских языков.
Протоязыки не сохранились в старинных текстах, но лингвисты, словно археологи, ищут невидимые нити, соединяющие сегодняшние языки с теми, что были до нас.
ИИ может ускорить этот процесс, становясь своеобразным детективом, который ищет закономерности, связывая современные и древние языки в единую картину. Он анализирует не просто слова, но целые структуры
и закономерности, которые на первый взгляд могут быть невидимы.
и закономерности, которые на первый взгляд могут быть невидимы.




Одной из главных трудностей в восстановлении протоязыков является отсутствие аудиозаписей. Мы не знаем, как они звучали, как их произносили носители. И здесь, в этот момент, вновь вступает ИИ.
ИИ может использовать современные и старые языки как тренировочные данные, чтобы реконструировать возможные звуки протоязыков. Нейросеть изучит звуковую систему, которая с течением времени трансформировалась в разные формы.
Нейросеть в силах моделировать звуковые изменения по аналогии с известными закономерностями, такими как законы фонетических изменений, используемые
в исторической лингвистике (например, законы звуковых чередований метатезы).
в исторической лингвистике (например, законы звуковых чередований метатезы).

Восстановление протоязыков — это работа с загадками прошлого. И вот, как ИИ может помочь с этим:
Скоро мы сможем не просто читать древние тексты, но и слышать их. А значит, восстановление протоязыков может стать не только научным открытием, но и мостом в историю, соединяющим нас с нашими далекими предками.

ИИ может обрабатывать огромные объемы текстов на разных языках (современных и древних), сравнивая лексический и грамматический состав
Алгоритмы могут автоматически выделять закономерности, такие как изменения звуков (графемы и фонемы), флексии или суффиксы
Используя методы статистического анализа, ИИ может предсказать,
как мог выглядеть общий предок
этих языков, и предложить гипотезы
о возможных лексических
и грамматических структурах
как мог выглядеть общий предок
этих языков, и предложить гипотезы
о возможных лексических
и грамматических структурах














Но, несмотря на все эти преграды, мы движемся вперёд.
И вот, шаг за шагом, на свет выходят первые примеры, когда ИИ действительно помогает разгадать эту древнюю тайну.
И вот, шаг за шагом, на свет выходят первые примеры, когда ИИ действительно помогает разгадать эту древнюю тайну.
NeuroCipher — нейросеть, которую создали учёные
из Массачусетского технологического института
и подразделения Google Brain. Процесс расшифровки следующий: сначала нейросеть-энкодер обрабатывает входные данные, преобразуя их в числа, а затем нейросеть-декодер генерирует ответ. Алгоритм протестировали на угаритском, иврите, критском и древних романских языках. Точность результатов составляет
от 66% до 92% в зависимости от выбранной письменности.
из Массачусетского технологического института
и подразделения Google Brain. Процесс расшифровки следующий: сначала нейросеть-энкодер обрабатывает входные данные, преобразуя их в числа, а затем нейросеть-декодер генерирует ответ. Алгоритм протестировали на угаритском, иврите, критском и древних романских языках. Точность результатов составляет
от 66% до 92% в зависимости от выбранной письменности.
Нейросеть уже помогает расшифровывать тексты, которые раньше казались непроходимыми. И это только начало. Мы находимся на грани того, чтобы вернуть забытые языки, восстановить культурные следы, которые казались утерянными навсегда.